











How Scraping Camel helps
Scraping Camel checks the HTML pages of a web page. It gets information from them. It saves this information and generates one output CSV file from it.
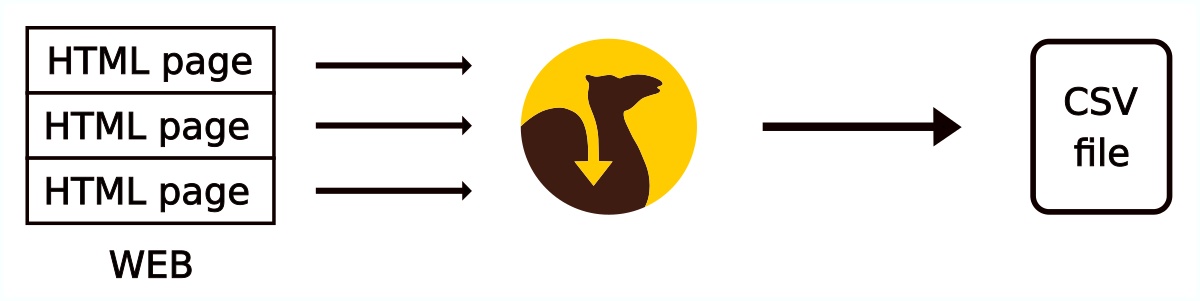
How Scraping Camel works
- The user defines the domain that the Camel is to check. E. g. "https://www.mergado.cz /`.
- The user verifies the domain - similar to Google. You can choose to insert a META tag into pages, a file on the web, or a DNS record. The goal is to prove that this is not a third-party site. It is not the goal of the application to scrap foreign sites.
- The user sets what elements he wants to get from the target HTML pages. The defaults are title, meta description, and so on. The menu is brief - because the user can define his elements. He sets them by either putting the HTML code in front of and behind the information or by using a regular expression. It's handy and allows you to get almost any information out of an HTML page.
- The user sets the names of the elements with the information obtained in the output CSV.
- Scraping Camel goes through the pages of the target domain. It requires a sitemap.xml from which the Camel takes the site information. It cannot be used without a sitemap.xml! It generates an output CSV file.
- Scraping Camel automatically goes through the target site gradually. If a new page appears, it will find and process it. If the information on the existing page changes, the Camel will project the changes into the output CSV after processing.
What is the output CSV good for
- SEO analysis, data analysis of products, categories, and the like. Wide range of use!
- It is possible to process even websites that are not online stores! Their data can be processed in Mergado for PPC DSA Google Ads or otherwise processed by the usual procedures for online stores!
- If the user's shop system does not generate XML (or other) feeds, it can obtain information as follows and further process it in Mergado for advertising systems.
Who is Scraping Camel for
- for agency marketing specialists
- for online store staff
- for SEO specialists, PPC experts...
Why you should use Scraping Camel
- It allows you to apply feed marketing workflows you know from online stores with XML feeds to sites without a cart.
- You get information that is on the web but not in the XML data feed.
- Unlike desktop SEO software, data is automated continuously, and data outputs are available online for other applications or data connections.
- Output CSV can be processed in Mergado or by another application.
- Great benefit of the obtained data.
What does Scraping Camel look like
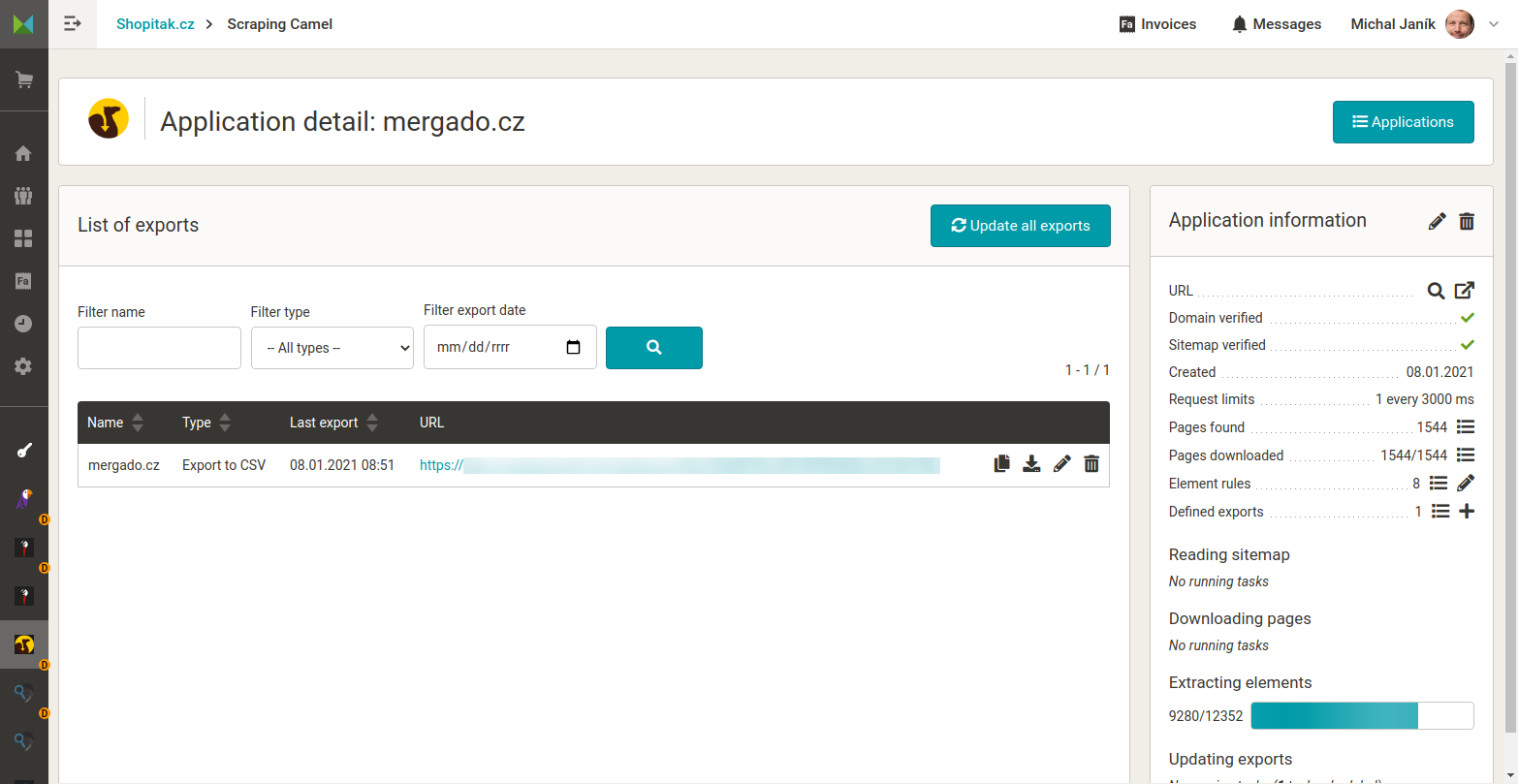
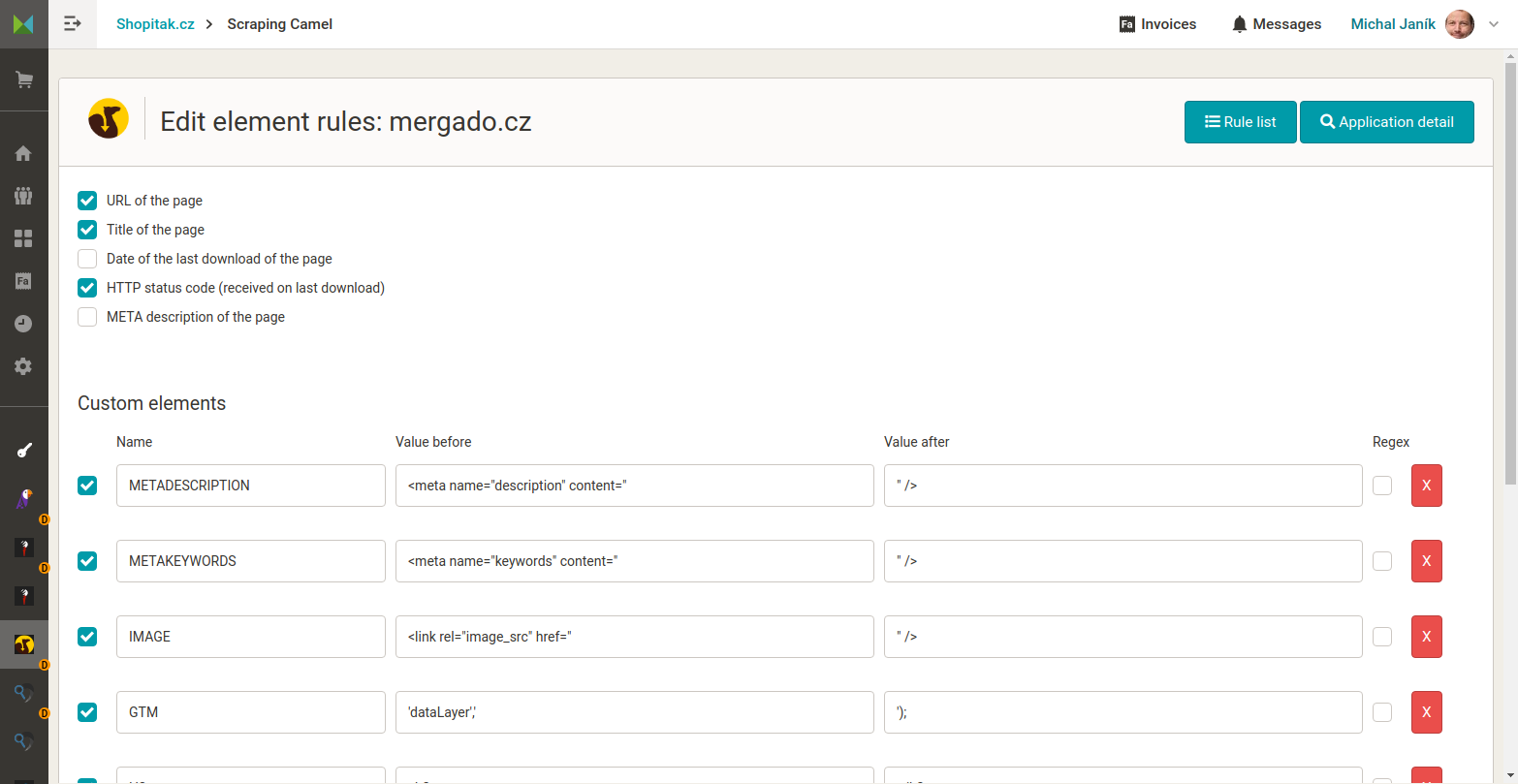
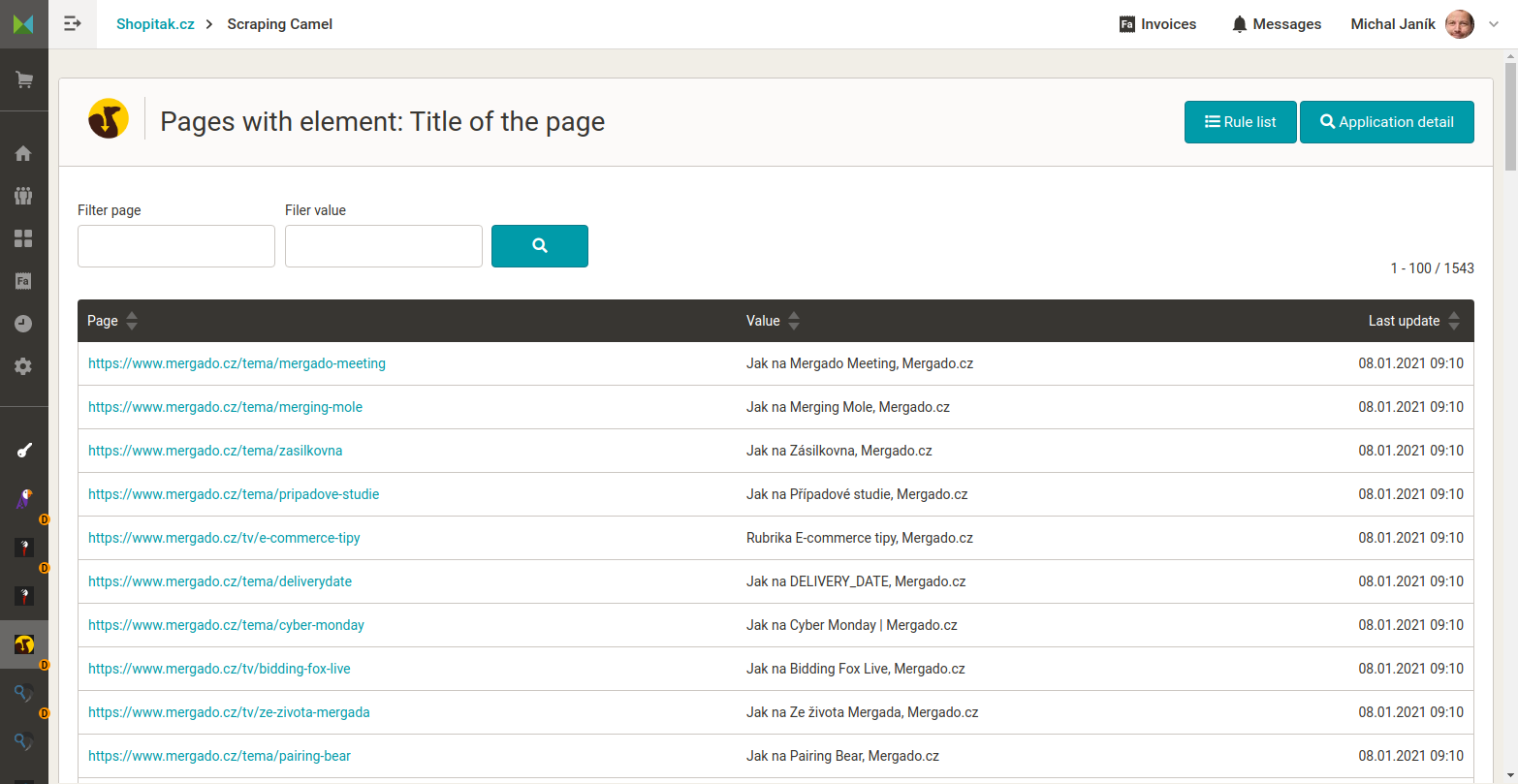
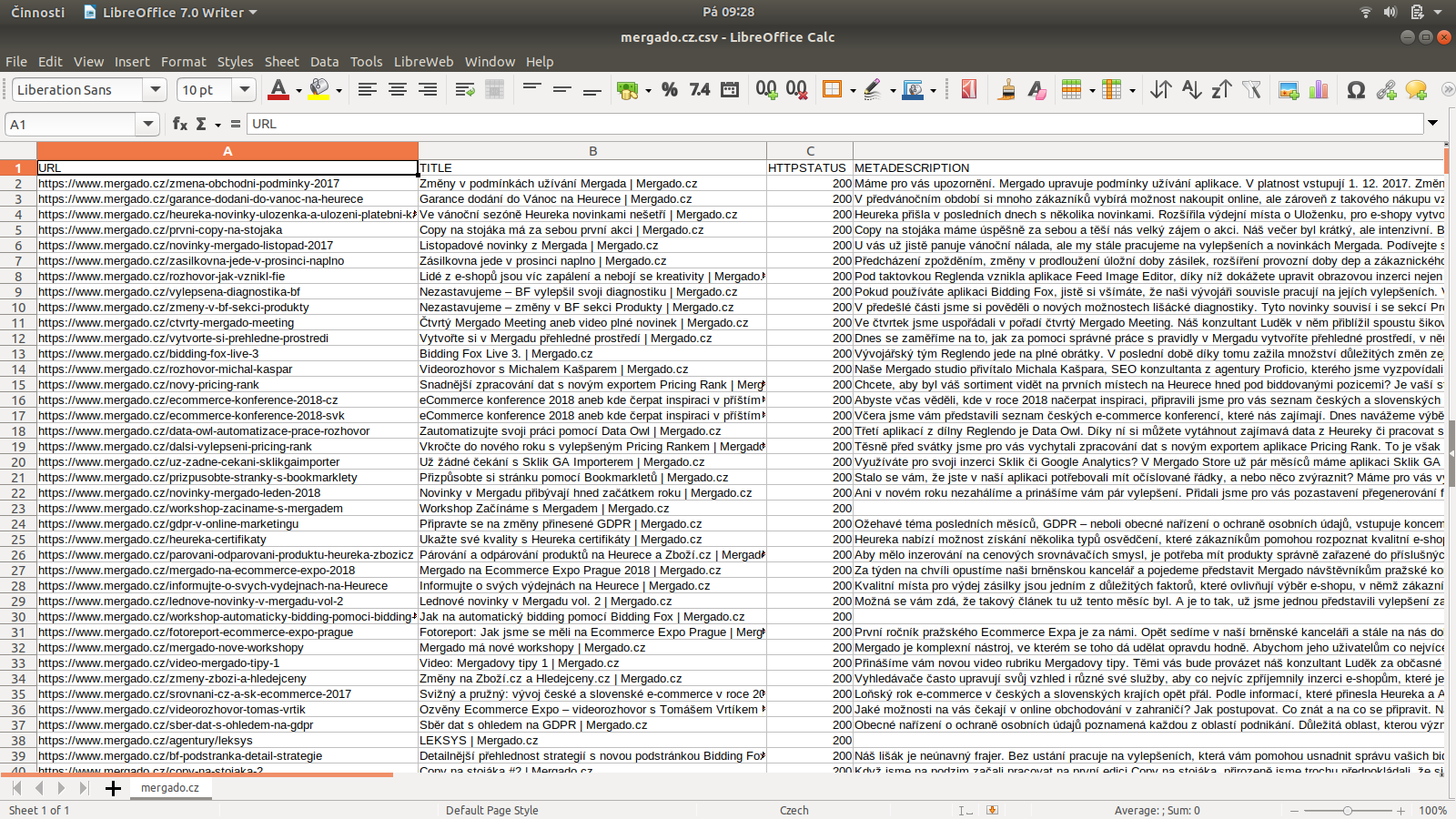
More information
- What data does Scraping Camel process - data privacy?
- Use of PPC Wolf is governed by the standard Mergado terms of use
- Application details
App rights
In order to work properly, the Scraping Camel app needs the following rights:
- Reading of user's online stores
- Reading user's data
- Reading project data
To activate this app it is first necessary log in.
Tips for working with Scraiping Camel.
Domain Verification
It's similar to Google. You have the following authentication options to choose from:
- insert the file into the root directory of the site
- insert META tag into pages
- DNS record
Sitemap.xml
Scrapping the site is done by the Camel downloading a Sitemap.xml. It obtains the site information from it and then visits it. The Camel gets the URL of the web pages only from a sitemap.xml. If the page is not in the sitemap, it will not find it.
Regular Expressions
Standard regular expressions are supported. You can test the expression, for example, at https://regex101.com/.
Compared to Mergado, the work with groups of characters is done differently. Groups are indicated in parentheses. In Mergado, you can write more parentheses, and in the graphical tool, you can select the content of which group you want to store in the variable. Scraping Camel does not support this. It always saves the first group it finds in the regular expression. However, a similar effect can be achieved by the following notation.
Let's say a user would like to get one regular expression from HTML code
<h1 class="page-header"><a id="content-scroll"></a>ABC</h1>
<h1>ABC</h1>
obtain the value of h1 as "ABC". The user has different types of HTML pages on the website, and the h1 main title is given once, see the first line, and twice, see the second line. The user could parse h1 into two elements. But he doesn't want that. He wants to get the data with one regular expression and write it to one element. He can use this notation.
<h1(?: class="page-header"><a id="content-scroll"></a)?>(.*)</h1>
Note that the first group in parentheses is marked with question marks so that it is understood as optional and not as a variable to be parsed.