
 CZ
CZ
 SK
SK
 EN
EN
 PL
PL
 HU
HU






Sbírejte data z vašeho e-shopu automaticky a využijte je pro výkonnější kampaně
Co rozšíření umí
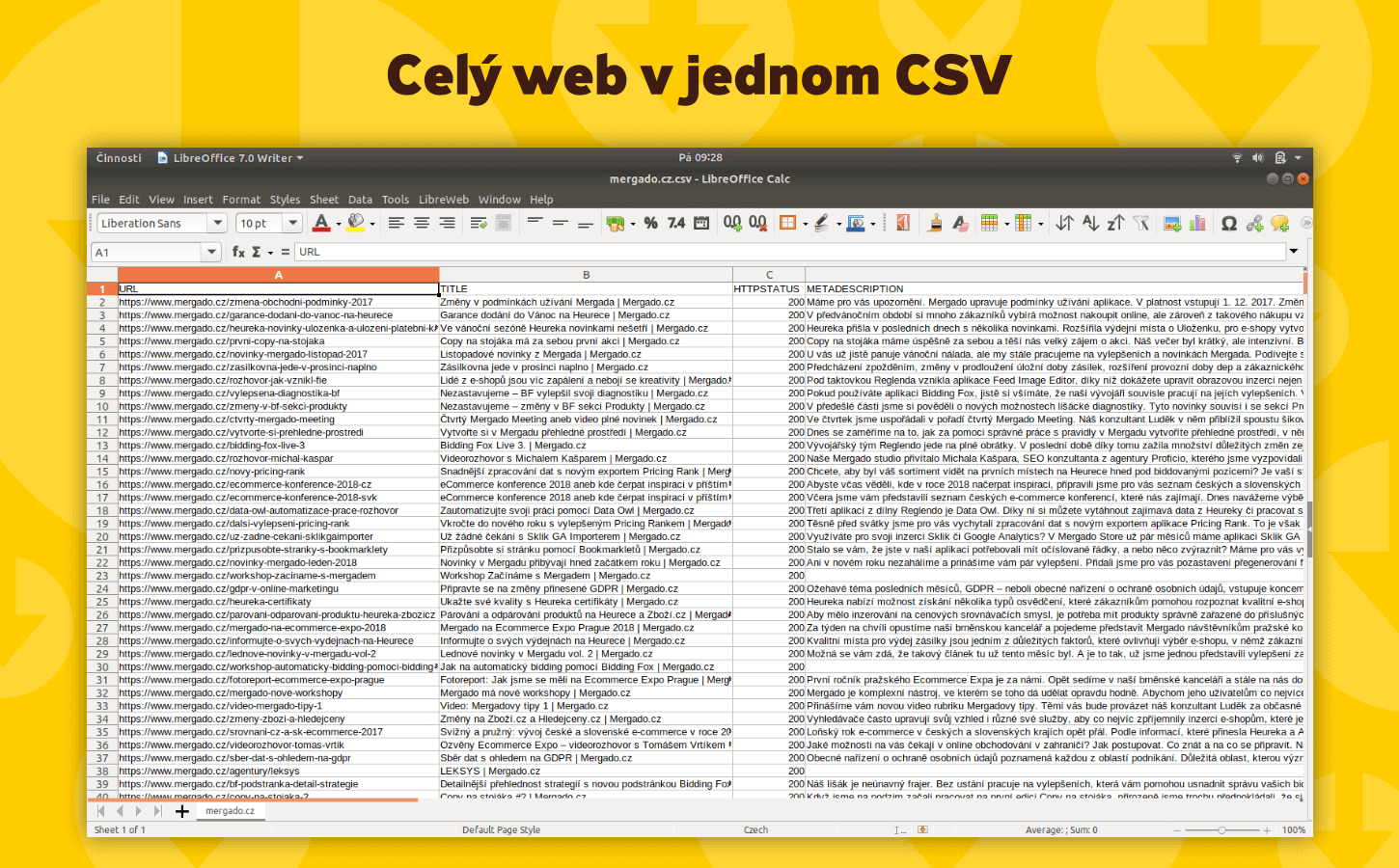
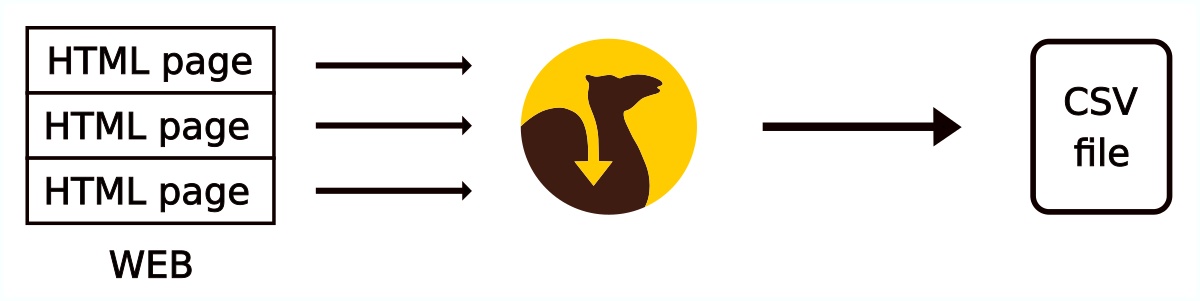
Scraping Camel pro vás z vašeho webu získá data, která potřebujete pro marketing, SEO nebo analýzy – rychle, přesně a bez ruční práce. Z HTML kódu vytáhne prvky, které běžné XML feedy neobsahují, například title, meta description, nadpisy nebo jiné elementy, které si sami určíte.
Všechna získaná data uloží do jednoho přehledného CSV souboru, se kterým můžete dál pracovat v Mergadu nebo jiných nástrojích. Díky nim snadněji zacílíte reklamy, zefektivníte SEO strategii a zvýšíte výkon inzerce. Rychlejší příprava kampaní, relevantní data a lepší výsledky pak znamenají vyšší zisky i úsporu času.
Hlavní funkce
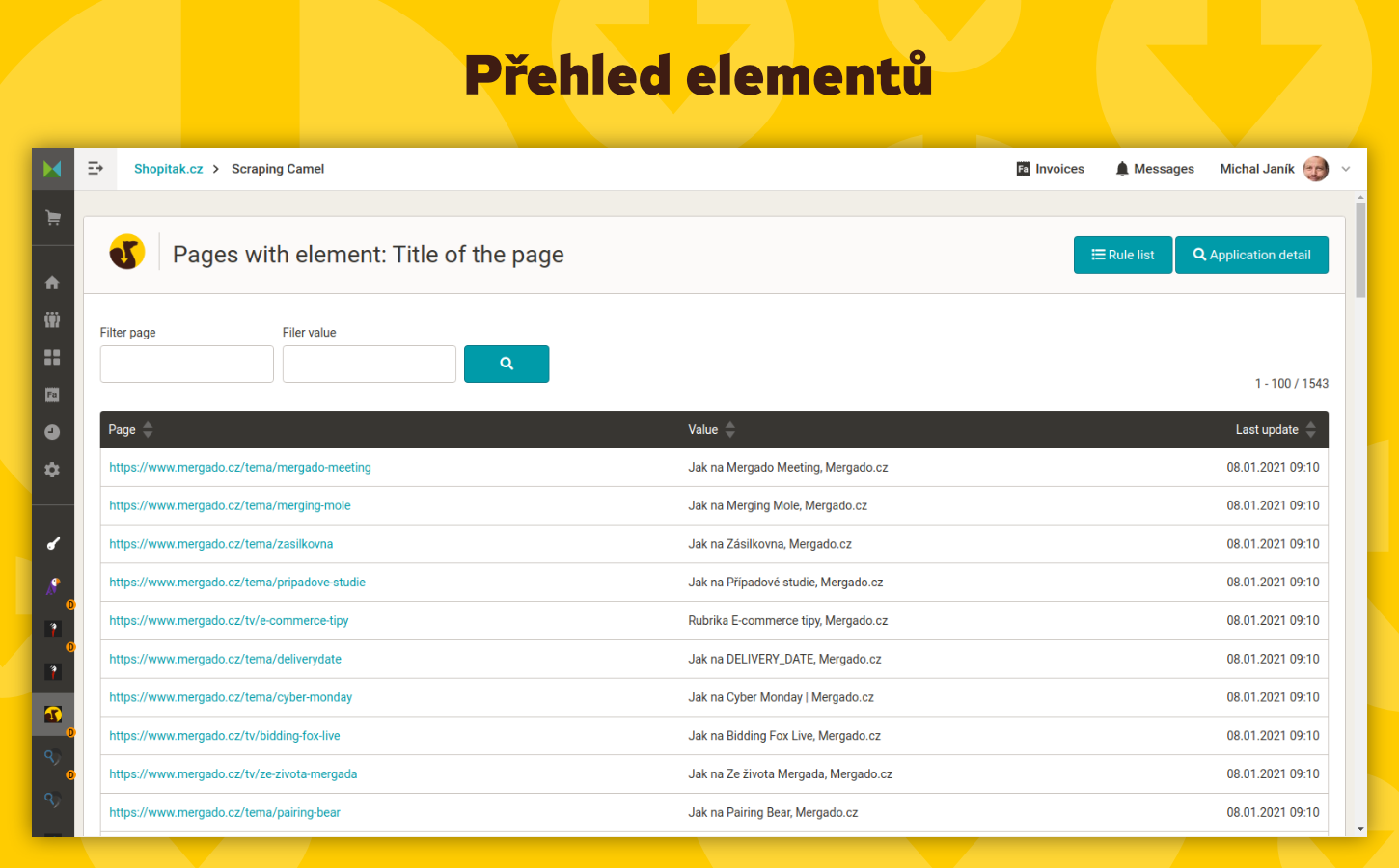
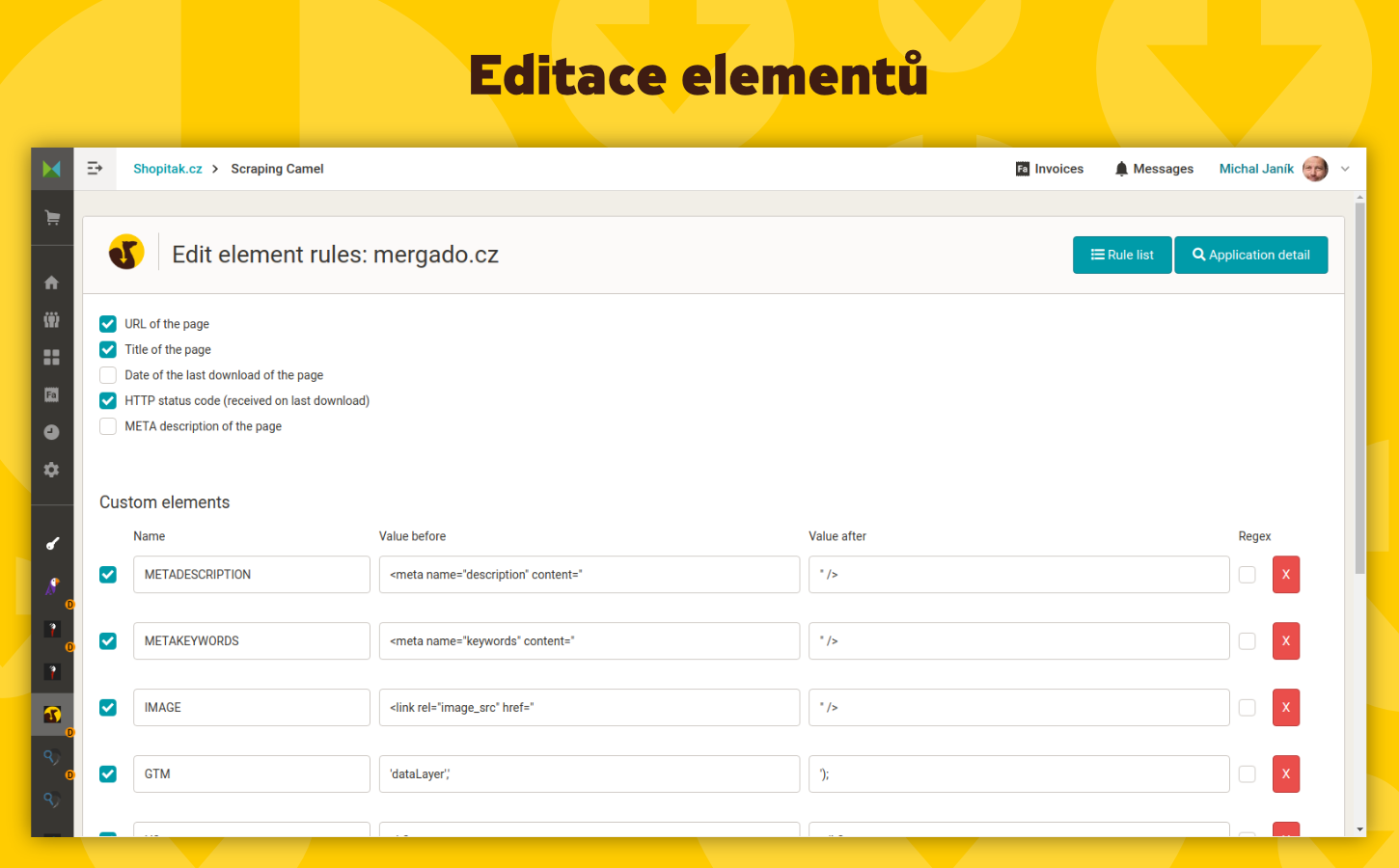
- Získávání libovolných dat – Získáte téměř libovolná data z vašich HTML stránek, a to i ta, která nejsou obsažena v tradičních XML feedech. To zahrnuje například TITLE, META DESCRIPTION, nadpisy H1 a H2, ID značky Google Analytics nebo Google Tag Manageru, kategorie stránky a štítky. Můžete si také definovat vlastní elementy buď pomocí textu před a za hledanými informacemi, nebo pomocí regulárních výrazů (viz FAQ).
- Rychlá kontrola dat – Scraping Camel automaticky prověří všechna získaná data a odhalí problémy, které by vám jinak unikly. Obsahuje přes 35 systémových validátorů pro klíčové oblasti SEO a navíc si můžete vytvořit vlastní, přesně na míru svým strategiím. Kontroly běží nepřetržitě, takže vy i váš tým máte aktuální výsledky kdykoliv po ruce.
- Využití hromadných elementů – Využívá hromadné elementy, s jejichž pomocí získá ze stránky všechny zpětné odkazy a všechny adresy obrázků, nejen jejich první výskyt. Díky tomu máte kompletní přehled a můžete je snadno validovat – odhalit nefunkční odkazy, příliš velké obrázky nebo obrázky bez popisku.
- Nepřetržitý provoz na serveru – Na rozdíl od desktopových nástrojů běží Scraping Camel nepřetržitě na serveru. Díky tomu máte data stále aktuální, dostupná a připravená k použití.
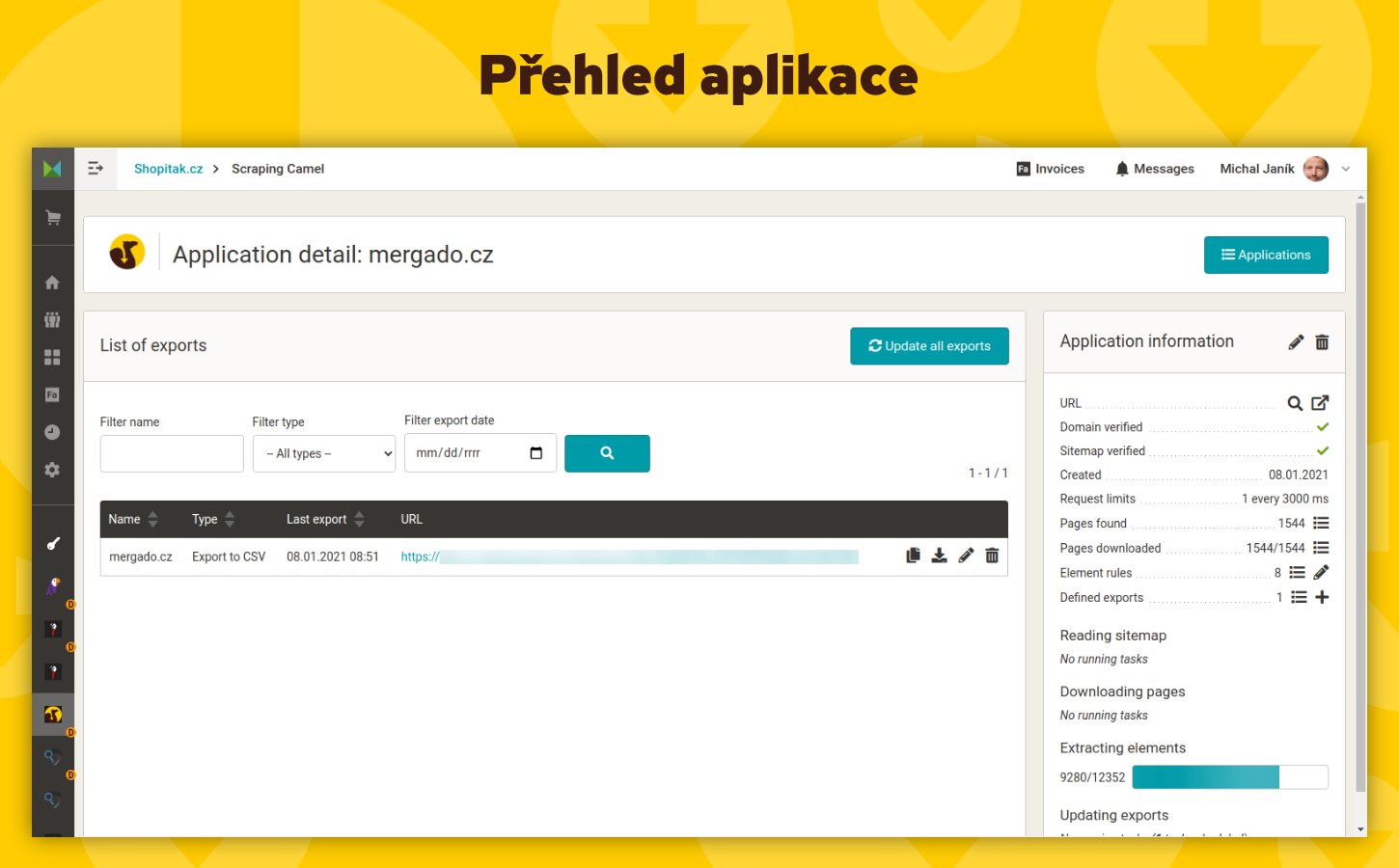
- Export do CSV a podpora Mergado Editoru – Získaná data vám připraví do jednoho CSV soubor, který můžete snadno dále zpracovávat v Mergado Editoru a kombinovat s daty z jiných zdrojů (např. Google Analytics) pro hlubší analýzy a reporty.
Pro koho je rozšíření vhodné
Toto rozšíření ocení zejména:
- Marketingové agentury, SEO a PPC specialisté, kteří chtějí specifická a aktuální data pro lepší cílení svých strategií.
- E-shopaři, kteří potřebují vytvořit produktové či dostupnostní feedy, doplňovat chybějící data do stávajících feedů nebo analyzovat stránky, pro které jejich shopsystém negeneruje feedy (např. kategorie, blogové články, statické stránky).
- Správci webů bez košíku (velkoobchodní katalogy zboží, nabídky zájezdů, kulturních akcí, online magazíny, firemní weby), kteří chtějí data využít pro marketingové kampaně a analýzy.
- Uživatelé, kteří potřebují vytvářet vlastní validátory a elementy pro specifickou SEO validaci a chápou přesah technického SEO do byznysu a marketingových strategií.
Co je potřeba k používání
Scraping Camel pracuje s HTML kódem vašich webových stránek. Nejdříve je potřeba ověřit přístup k doméně, aby se zabránilo zneužití a shromažďování dat z cizích webů. Ověření lze provést pomocí DNS TXT záznamu, META značky, HTML souboru nebo přes Google Search Console.
Další podmínkou fungování je vložení funkčního souboru sitemap.xml, ze kterého Scraping Camel získává URL adresy stránek k procházení.
Příklady využití
Chcete spustit Performance Max kampaně v Google Ads, ale nemáte potřebné page feedy? Scraping Camel je za vás vytvoří přímo z vašeho webu – automaticky stáhne všechny potřebné URL a další nezbytná data a připraví je ve správném formátu pro Google.
Nezobrazujete se zákazníkům ve vyhledávání na Googlu, ale nevíte proč? Scraping Camel projde vaše stránky a ukáže konkrétní problémy – třeba chybějící nadpisy, nefunkční odkazy nebo stránky, které se načítají příliš pomalu. Díky přehlednému reportu snadno zjistíte, co brání lepšímu umístění ve vyhledávačích, a můžete rovnou začít s opravami.
Vyzkoušejte ho hned
Vyzkoušejte Scraping Camel a využijte data, které vám běžné XML feedy neukážou. Prvních 30 dní jej můžete využívat zdarma. Pokud ho během této doby vypnete, nezaplatíte ani korunu.
FAQ
- Jaká je cena za používání Scraping Camel? Cena za rozšíření Scraping Camel je 986 Kč za měsíc při měsíční fakturaci. Při roční fakturaci je to 788,80 Kč za měsíc.
- Je cena stanovena za projekt nebo za e-shop v Mergado Editoru? Cena je platná pro jeden e-shop v Mergado účtu, bez ohledu na počet projektů v něm vytvořených.
- Jaká je zkušební doba pro Scraping Camel? Scraping Camel má třicetidenní zkušební dobu, ve které si zvládnete vyzkoušet všechny dostupné funkce.
- Co je Scraping Camel a k čemu slouží? Scraping Camel automaticky prochází vaše webové stránky, získává z nich libovolná data (i taková, která v běžných XML feedech nejsou) a ukládá je do jednoho CSV souboru. Ty pak můžete využít pro SEO analýzy, datové analýzy produktů a kategorií nebo tvorbu PPC kampaní.
- Je možné použít Scraping Camel i pro weby, které nejsou e-shopy? Ano, Scraping Camel dokáže zpracovat i weby bez košíku, jako jsou například velkoobchodní katalogy zboží, online magazíny, katalogy zájezdů nebo firemní weby.
- Jak se Scraping Camel liší od desktopových crawlerů? Na rozdíl od desktopových nástrojů, které se spouštějí jednorázově na lokálním počítači, Scraping Camel běží na serveru nonstop a zajišťuje průběžnou aktualizaci dat, která jsou neustále dostupná online pro další zpracování.
- Jaká data mohu ze stránek získávat? Můžete získávat téměř libovolná data z HTML stránek, včetně TITLE, META DESCRIPTION, H1, H2, ID Google Analytics nebo Google Tag Manageru, kategorie, štítky, autora, počet komentářů, drobečkovou navigaci, cenu zboží, měnu a mnoho dalších. Je možné definovat i vlastní elementy.
- Jak funguje ověření domény? Pro zajištění, že Scraping Camel zpracovává pouze vaše weby, je nutné ověřit vlastnictví domény. To jde udělat vložením DNS TXT záznamu, META značky do stránek, HTML souboru na web nebo propojením přes Google Search Console.
- Musím mít soubor sitemap.xml? Ano, sitemap.xml je podmínkou pro fungování rozšíření, protože Scraping Camel z něj získává URL adresy stránek k procházení.
- Co jsou „AI elementy“ ve Scraping Camelu a k čemu slouží? AI elementy využívají umělou inteligenci a algoritmy k automatickému získávání obsahu bez ruční definice. Dokáží generovat klíčová slova (jednoslovná, dvojslovná, víceslovná), detekovat jazyk stránky (SC_DETECTED_LANGUAGE), počet slov (SC_NUMBER_OF_WORDS) a hlavní titulek (SC_MAIN_TITLE).
- Co je interní validace dat a jak mi pomůže? Interní validace umožňuje rychlejší a jednodušší kontrolu dat přímo ve Scraping Camelu. Rozšíření obsahuje přes 35 systémových validátorů pro SEO metriky (metadata, indexovatelnost, rychlost načítání, chybové URL) a můžete si také vytvořit vlastní validátory. Pomáhá identifikovat technické problémy a zlepšovat SEO.
- Co jsou „Hromadné elementy“ ve Scraping Camelu? Hromadné elementy umožňují získat všechny výskyty určitého prvku ze stránky, nejen jejich první výskyt. Jde o všechny zpětné odkazy a všechny adresy obrázků. Ty je možné následně validovat pro odhalení nefunkčních odkazů nebo příliš velkých obrázků.
- Poskytují se získaná data z mého webu někomu dalšímu? Scraping Camel neposkytuje data získaná z webů uživatelů nikomu cizímu. Po smazání webu v rozšíření dojde také ke smazání dat, která jsou po omezenou dobu držena pouze v zálohách pro případ obnovení.
- Jak Scraping Camel pracuje s regulárními výrazy? Podporovány jsou standardní regulární výrazy, kterési můžete vyzkoušet například na stránce https://regex101.com/. Oproti Mergado Editoru je ve Scraping Camelu práce se skupinami znaků řešena jinak. Skupiny se označují závorkami. V Mergadu můžete zapsat více závorek a v grafickém nástroji vybrat obsah té skupiny, kterou chcete uložit do proměnné. Scraping Camel toto nepodporuje. Vždy uloží pouze první skupinu, kterou v regulárním výrazu najde. Podobného výsledku můžete dosáhnout následujícím zápisem:
Představte si, že chcete jedním regulárním výrazem získat z následujícího HTML kódu hodnotu h1 ve znění „ABC“.
<h1 class="page-header"><a id="content-scroll"></a>ABC</h1><h1>ABC</h1>Na webu máte různé typy HTML stránek a hlavní nadpis h1 se jednou nachází v první variantě kódu a podruhé ve druhé. Mohli byste si parsovat h1 do dvou elementů, to ale nechcete. Chcete data získat jedním regulárním výrazem a uložit je do jednoho elementu. Můžete použít tento zápis:<h1(?: class="page-header"><a id="content-scroll"></a)?>(.*)</h1>První skupina v závorkách je označena otazníky tak, že se chápe jako volitelná a není brána jako proměnná k uložení.
Správa
Pro aktivaci tohoto rožíření je nutné se nejdříve přihlásit .