
 EN
EN
 CZ
CZ
 SK
SK
 PL
PL
 HU
HU







Collect data from your online store automatically and use it for more effective campaigns
What the extension can do
Scraping Camel gathers the data you need from your website for marketing, SEO, or analytics – quickly, accurately, and without manual work. From the HTML code, it extracts elements that standard XML feeds don’t include, such as title, meta description, headings, or other elements you define yourself.
All collected data is stored in one clear CSV file, which you can further process in Mergado or other tools. This makes it easier to target ads, optimize your SEO strategy, and boost ad performance. Faster campaign preparation, relevant data, and better results then mean higher profits and time savings.
Key features
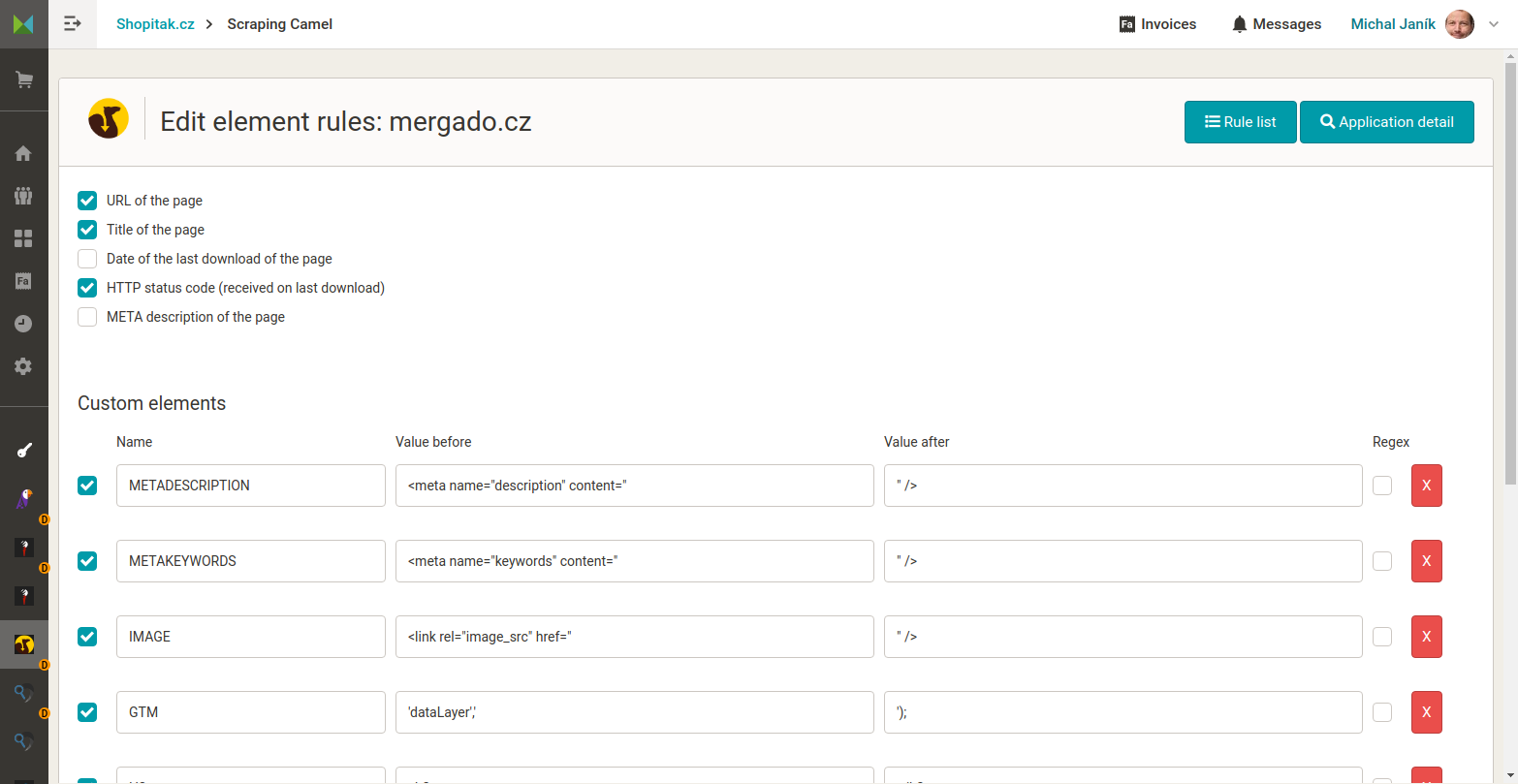
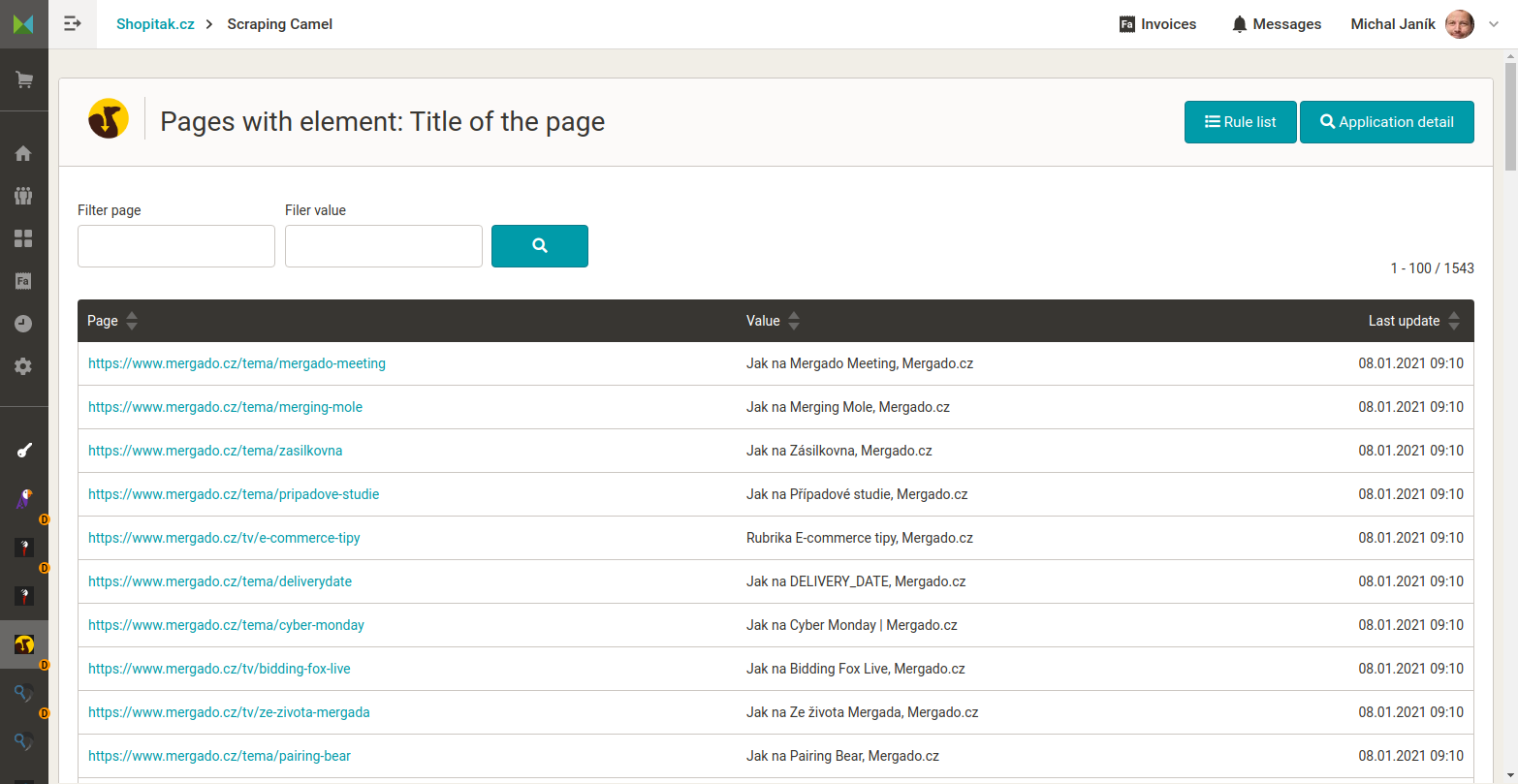
- Extracting any data – Gather almost any data from your HTML pages, including those not available in traditional XML feeds. This includes TITLE, META DESCRIPTION, H1 and H2 headings, Google Analytics or Google Tag Manager IDs, page categories, and tags. You can also define your own elements either by using text before and after the desired information, or by using regular expressions (see FAQ).
- Fast data checks – Scraping Camel automatically verifies all collected data and reveals issues you might otherwise miss. It includes over 35 system validators for key SEO areas, plus you can create your own, tailored exactly to your strategies. Checks run continuously, so you and your team always have up-to-date results at hand.
- Use of bulk elements – Utilizes bulk elements to extract all backlinks and all image URLs from a page, not just the first occurrence. This gives you a complete overview and makes validation easier – spotting broken links, oversized images, or images without alt text.
- Continuous server operation – Unlike desktop tools, Scraping Camel runs continuously on the server. This ensures your data is always up-to-date, accessible, and ready to use.
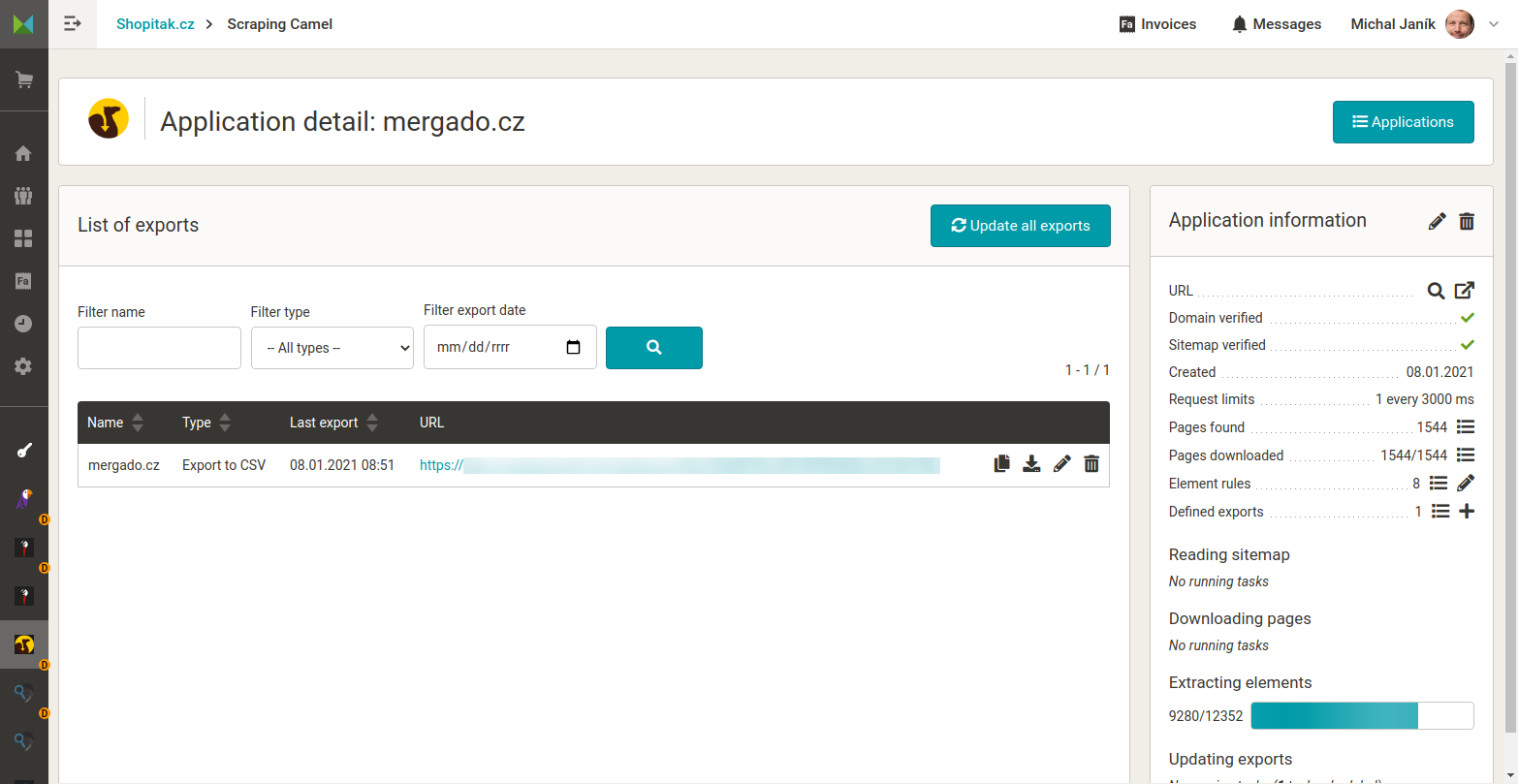
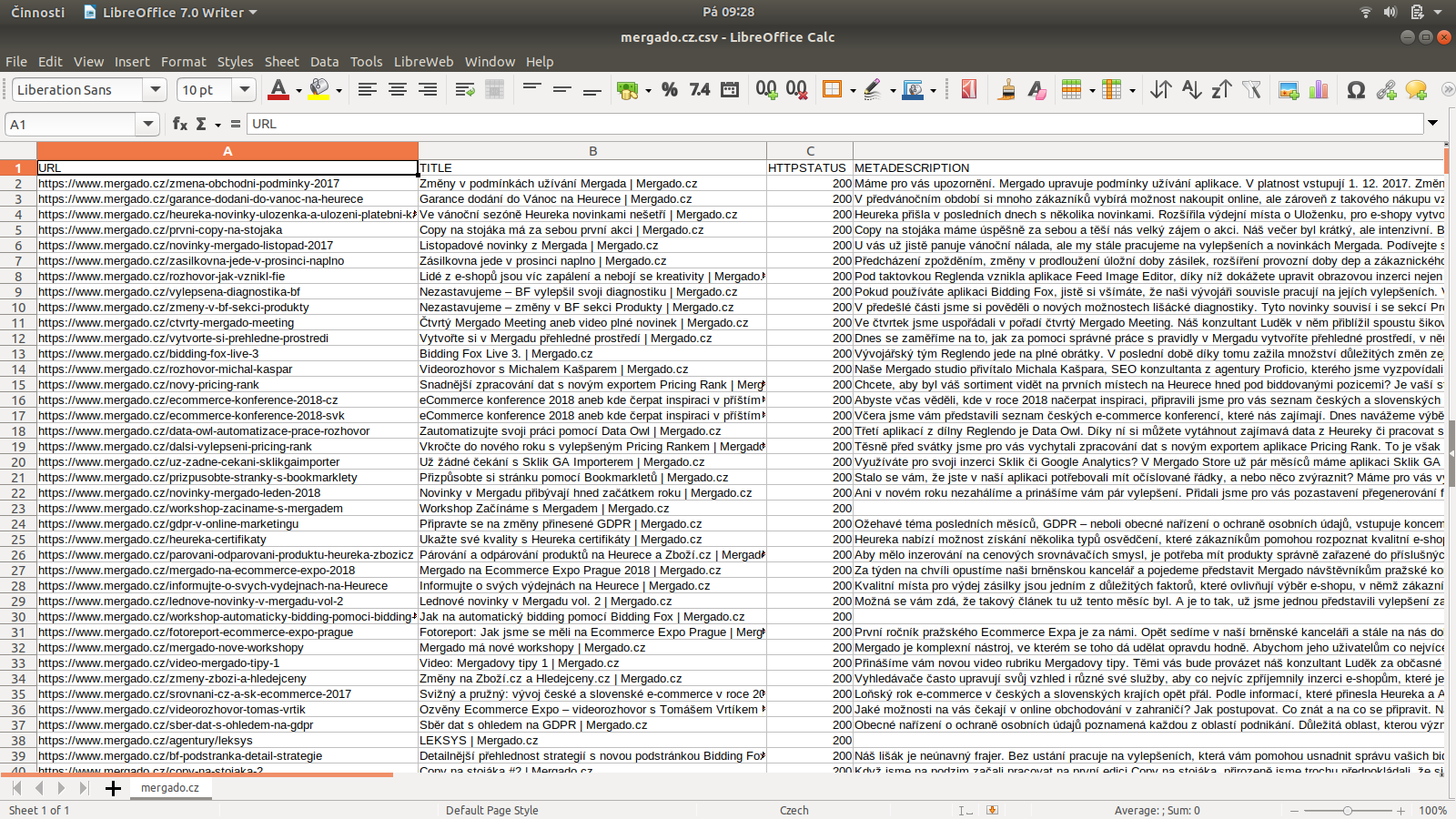
- Export to CSV and Mergado Editor support – Collected data is prepared in a single CSV file that you can easily process further in the Mergado Editor and combine with data from other sources (e.g., Google Analytics) for deeper analyses and reports.
Who is the extension for
This extension is especially useful for:
- Marketing agencies, SEO and PPC specialists who want specific and up-to-date data for better targeting of their strategies.
- Online store owners who need to create product or availability feeds, add missing data to existing feeds, or analyze pages for which their shop system doesn’t generate feeds (e.g., categories, blog posts, static pages).
- Website administrators without shopping carts (wholesale product catalogs, travel offers, cultural events, online magazines, company websites) who want to use data for marketing campaigns and analysis.
- Users who need to create their own validators and elements for specific SEO validation and who understand the overlap of technical SEO with business and marketing strategies.
What you need to use it
Scraping Camel works with the HTML code of your website. First, you need to verify access to the domain to prevent misuse and data collection from third-party websites. Verification can be done via DNS TXT record, META tag, HTML file, or through Google Search Console.
Another requirement for operation is providing a functional sitemap.xml file, from which Scraping Camel retrieves the page URLs to crawl.
Use cases
Want to launch Performance Max campaigns in Google Ads but don’t have the necessary page feeds? Scraping Camel will generate them directly from your website – automatically downloading all required URLs and other essential data and preparing them in the right format for Google.
Not appearing to customers in Google search and don’t know why? Scraping Camel will crawl your site and reveal specific issues – such as missing headings, broken links, or slow-loading pages. With the clear report, you’ll easily identify what’s holding back better search rankings and can start fixing it right away.
Try it now
Try Scraping Camel and access data that standard XML feeds won’t show you. The first 30 days are free. If you cancel within this period, you won’t pay a cent.
FAQ
- What is the price of using Scraping Camel? The price of the Scraping Camel extension is EUR 37 per month with monthly billing. With annual billing, it’s EUR 29.60 per month.
- Is the price set per project or per online store in the Mergado Editor? The price applies to one online store in a Mergado account, regardless of the number of projects created within it.
- What is the trial period for Scraping Camel? Scraping Camel has a 30-day trial period, during which you can test all available features.
- What is Scraping Camel and what is it used for? Scraping Camel automatically crawls your website, extracts any data (including those not available in standard XML feeds), and stores them in a single CSV file. You can then use these for SEO analysis, product and category data analysis, or PPC campaign creation.
- Can Scraping Camel be used for websites that are not online stores? Yes, Scraping Camel can also process non-e-commerce sites, such as wholesale product catalogs, online magazines, travel catalogs, or company websites.
- How does Scraping Camel differ from desktop crawlers? Unlike desktop tools that run one-off on a local computer, Scraping Camel runs continuously on the server and ensures ongoing data updates, which are always available online for further processing.
- What kind of data can I extract from pages? You can extract almost any data from HTML pages, including TITLE, META DESCRIPTION, H1, H2, Google Analytics or Google Tag Manager IDs, categories, tags, author, number of comments, breadcrumbs, product price, currency, and many more. It is also possible to define your own elements.
- How does domain verification work? To ensure that Scraping Camel only processes your websites, it is necessary to verify domain ownership. This can be done by adding a DNS TXT record, inserting a META tag into the site, uploading an HTML file to the website, or connecting via Google Search Console.
- Do I need a sitemap.xml file? Yes, sitemap.xml is required for the extension to work, as Scraping Camel uses it to obtain the URLs of the pages to crawl.
- What are “AI elements” in Scraping Camel and what are they used for? AI elements use artificial intelligence and algorithms to automatically extract content without manual definition. They can generate keywords (single-word, two-word, multi-word), detect the page language (SC_DETECTED_LANGUAGE), count words (SC_NUMBER_OF_WORDS), and identify the main title (SC_MAIN_TITLE).
- What is internal data validation and how does it help me? Internal validation allows faster and easier data checks directly in Scraping Camel. The extension includes over 35 system validators for SEO metrics (metadata, indexability, loading speed, error URLs), and you can also create your own validators. It helps identify technical issues and improve SEO.
- What are “Bulk elements” in Scraping Camel? Bulk elements allow you to extract all occurrences of a specific element from a page, not just the first one. This includes all backlinks and all image URLs. These can then be validated to detect broken links or oversized images.
- Are the data collected from my website shared with anyone else? Scraping Camel does not share data collected from users’ websites with anyone else. When a website is deleted in the extension, the data are also deleted, and are only retained in backups for a limited time for recovery purposes.
- How does Scraping Camel work with regular expressions? Standard regular expressions are supported, and you can test them, for example, at https://regex101.com/. Compared to Mergado Editor, Scraping Camel handles character groups differently. Groups are marked with parentheses. In Mergado, you can write multiple parentheses and then use the graphical tool to choose which group’s content you want to save into a variable. Scraping Camel does not support this. It always saves only the first group it finds in the regular expression. A similar result can be achieved with the following expression:
Imagine you want to extract the value of h1 as “ABC” from the following HTML code using a single regular expression.
<h1 class="page-header"><a id="content-scroll"></a>ABC</h1><h1>ABC</h1>On your website, you may have different types of HTML pages, where the main h1 header sometimes appears in the first version of the code and sometimes in the second. You could parse h1 into two separate elements, but that’s not what you want. Instead, you want to capture the data with one regular expression and save it into a single element. You can use this expression:<h1(?: class="page-header"><a id="content-scroll"></a)?>(.*)</h1>The first group in parentheses is marked with question marks, making it optional and ensuring it is not treated as a variable to be captured.
Administration
To activate this extension it is first necessary log in .